
Data, Pipelines, The second POC - A JP-EN Dictionary
Creating Sakuryo’s Dictionary
In my ideas post I mentioned that the app will need data sources and a way to query them though a catalog/dictionary
- A catalog/dictionary for looking up words that is aware of what you know and remembers what you search
- Must be at least as good as any dictionary I use now; I must want to use it.
I now have a first POC to show and it is really almost good enough to use now! It still lacks the required data to create a good enough EN -> JP search ranking but the JP -> English is spot on!
Also, I will need a new data processing pipeline to generate all the correct furigana for each kanji reading to send to the front end.
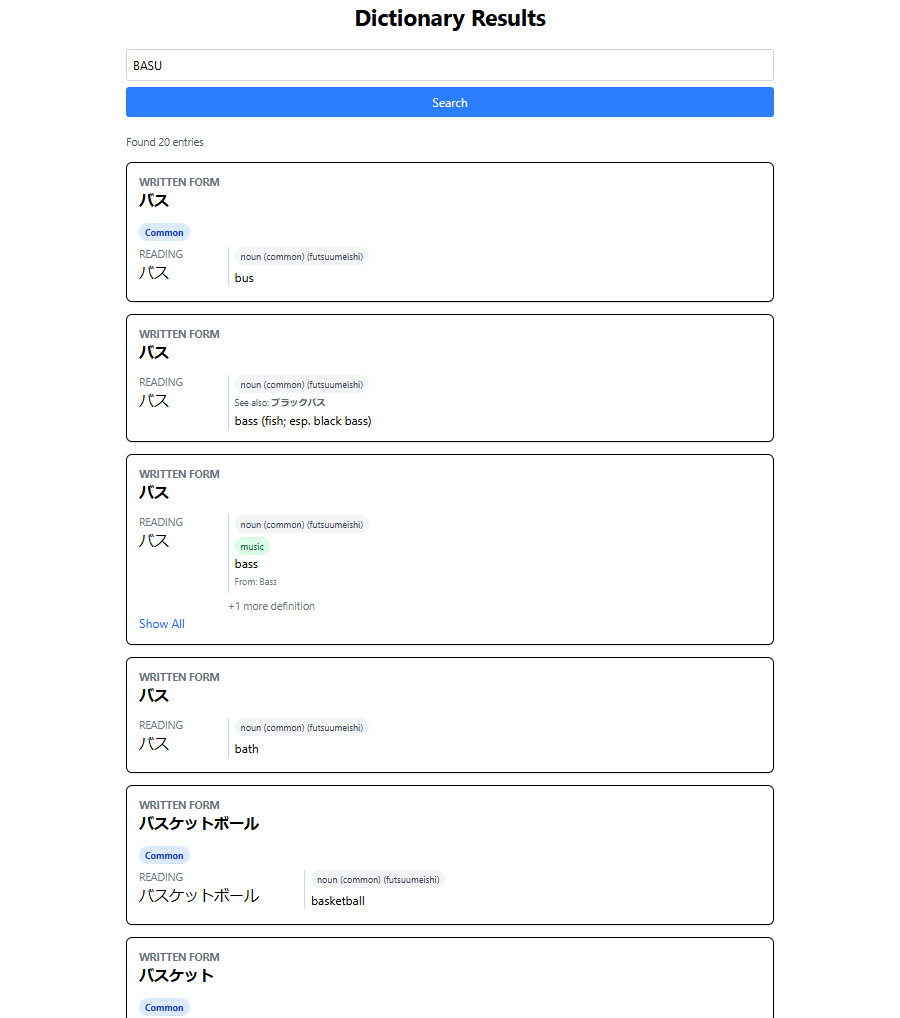
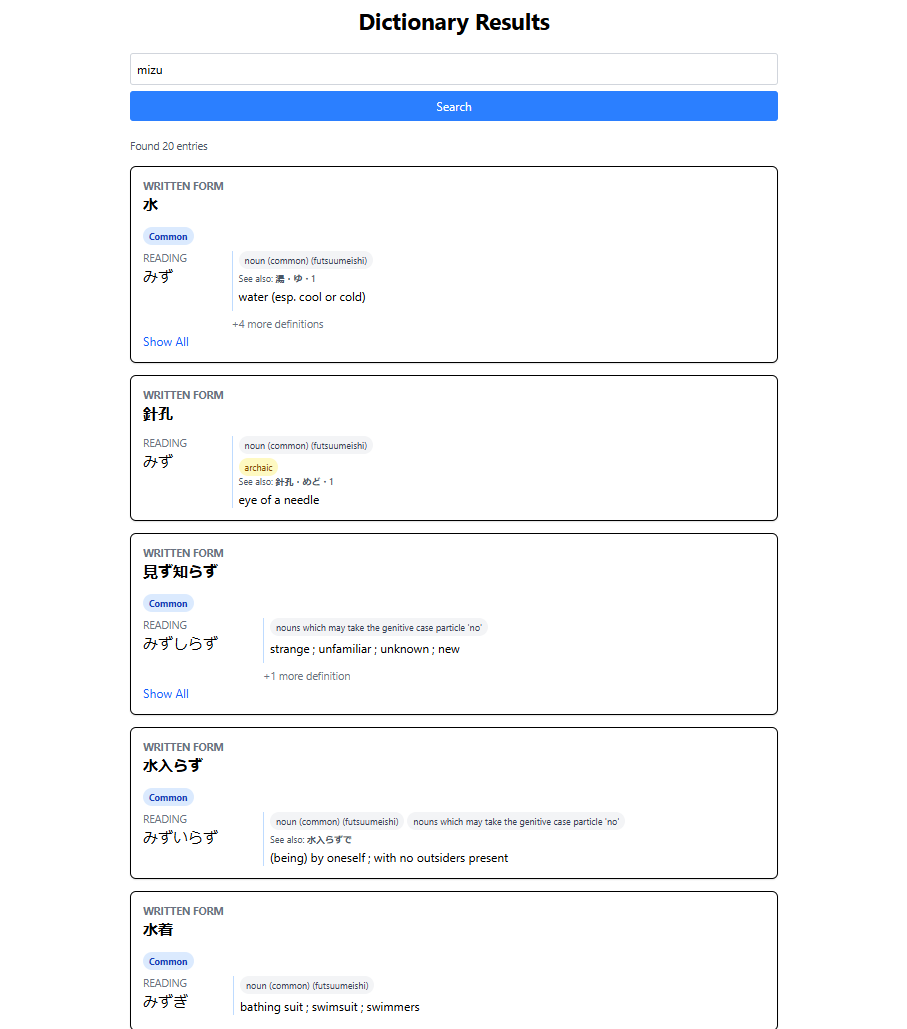
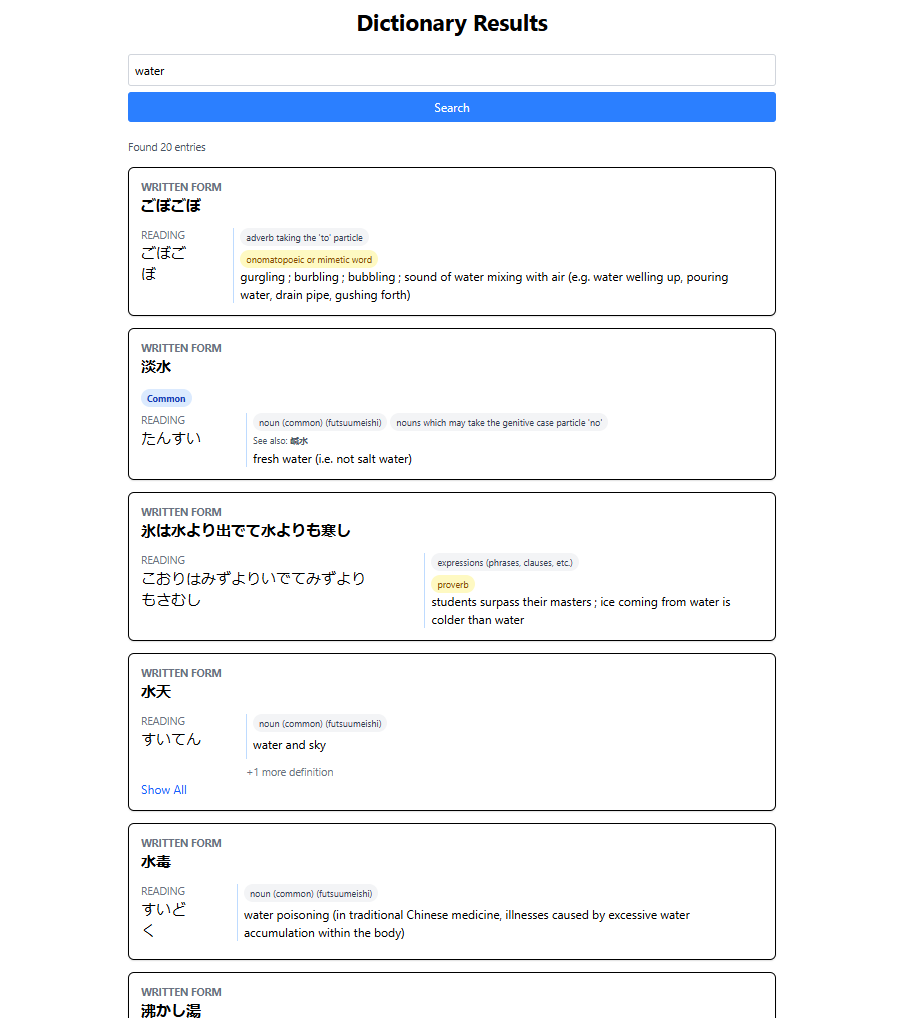
I think I will pause development on the dictionary for a little while and focus more on data. This time I want many pipelines and data, more than the two ETL ones I just built. Progress is looking good.
I am realizing that my development style might not be very appealing to most, I am attempting the problems and tasks I am least sure I can accomplish myself, first. I should also maybe focus on some wireframes at least soon to have a better target for what the application at an MVP state can do. But instead, I will work on some data pipelines.